The number of library-related RSS and Atom applications is increasing daily. But, as yet, the formats and technology involved are far from stable. This article looks at the current state of the field, discusses future developments and considers implications for the library.
RSS has been around since 1997 but relatively little attention was paid to it until it became a central component of the new craze of weblogging or blogging. The RSS technology landscape is confused. There isn't even consensus as to the meaning of the acronym RSS: is it Really Simple Syndication, RDF Site Summary or Rich Site Summary? Despite this, RSS is becoming increasingly influential in the library where it is recognised as a useful tool for a growing number of tasks.
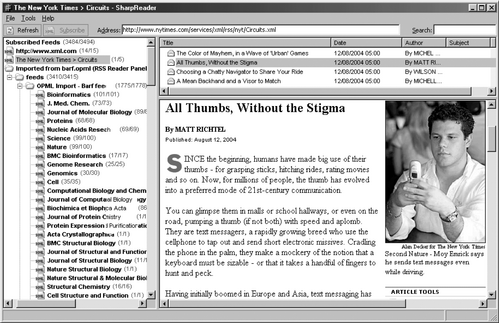
In essence, RSS is a simple XML syntax for describing a channel or feed of recent additions to a website. These additions may be news items, blog updates, library acquisitions or any other discrete information elements. The RSS feed, in the form of an XML file, is made available on the web site; a site with one or more feeds is said to be syndicated. Users subscribe to the feed using an aggregator or newsreader that polls the site on a regular basis, maybe once a week, maybe once every quarter of an hour. The aggregator displays feeds and enables users to organise them and to access related Web pages when these are available. For example, the New York Times circuits feed [1] summarises the newspaper's most recent computer technology-related articles and provides links back to NYTimes.com for the full article, as illustrated in Figure 1. The aggregator shown is SharpReader [2] which is free, simple to install and intuitive to use.
Atom [3] is an increasingly popular rival to RSS. Unless otherwise stated, comments in this article concerning RSS are also relevant to Atom.
The number of library-related uses of RSS is increasingly exponentially [4], as illustrated by the following subsections. The categories overlap in places and, no doubt, new categories will have appeared before this article is in print.
Blogs are web-based journals. Not surprisingly, given the librarian's role as communicator, there is a proliferation of blogs in the library world. This is illustrated by Peter Scott's lengthening list of Library Weblogs [5]. Fichter (2003) gives useful practical advice on "Why and how to use blogs to promote your library's services". Maintaining a blog feed means that those interested can be informed when the blog is updated. Blog software often includes RSS feed generation.
RSS can also be useful for more formal announcements. For example, libraries at the University of Oxford provide a feed [6] with announcements such as changes in opening hours and the introduction of new facilities. Library suppliers are following suit. Talis [7], the library management systems company, provides a feed of company news.
It's relatively simple to make a feed available [8]. An RSS file is created, placed somewhere sensible on the web site in question and, most importantly, updated when the site is updated. Applications such as UKOLN's RSS-express editor [9] can simplify this process. If site content is stored in a database, it is often best to generate an RSS file directly from that database whenever it's updated with new content.
RSS is ideal for making announcements concerning library resources, particularly web-based ones. The Librarians' Index to the Internet (LII) [10] is a "searchable, annotated subject directory of more than 14,000 Internet resources selected and evaluated by librarians for their usefulness to users of public libraries". It maintains a feed listing "new and newly-discovered web sites".
The content of existing feeds is regularly used by librarians to answer queries, particularly those relating to current affairs. In late 2003, the Government of Canada was the first national government to provide an RSS-syndicated Newsroom [11]. Various feeds are available on topics such as national and regional news.
RSS is cropping up in numerous roles relating to books and monographs, from reviews to new book acquisitions [12]. The library at the University of Kent is one of the latest to provide an RSS feed detailing new book acquisitions [13]. And Amazon.com Syndicated Content [14] offers RSS feeds listing the top ten best sellers in various categories of books and other products.
As well as producing its own feeds and searching those of other sites, the library can provide a useful service by collating feeds and making them available to the end user. This can be done in two ways:
Peter Scott's Library Weblogs is an LIS example of the former. A more general example is Syndic8 [15], a useful source of RSS and Atom news feeds on a variety of topics.
The second and more common method of collating feeds is illustrated by sites such as LISFeeds.com [16]. This RSS headline aggregator "scrapes headlines from sites and services that specialize in library oriented news". The headlines are not presented as RSS files but are incorporated into the HTML of the LISFeeds site. EEVL's OneStep Industry News service [17] is another example. As can be seen in Figure 2, it gathers news headlines from feeds produced by a variety of engineering-related organisations. Again, the headlines are incorporated into the HTML of the EEVL site. Clicking on a headline takes the user to the site providing the relevant feed.
There are free tools available to facilitate the creation of this second form of portal. The UKOLN's RSSxpress Lite [18], for example, is a basic tool for placing any RSS channel onto a web site using a single line of JavaScript. The DOIS [19] provides JavaScript versions of feeds to Ariadne, the D-Lib Magazine, Information Research and the Journal of Digital Information. It also gives instructions as to how to incorporate the JavaScript in HTML web pages, so making the feeds available without having to " worry about parsing XML".
The Usenet newsgroups have been an important component of the Internet since the early 1980 s. They are now hosted by Google and are known as Google Groups [20]. In the Beta version of Google Groups 2, Atom feeds have been added to thousands of the newsgroups [21].
My.PubMed [22] is a search interface to PubMed, the free MEDLINE database. My.OAI [23] is a similar interface, this time to a selection of metadata databases from the Open Archives Initiative project [24]; databases include arXiv, Biomed Central and OCLC's Experimental Thesis Catalog. Both my.PubMed and my.OAI enable the download of search results in RSS format. The use of RSS in the presentation of search results is likely to become increasingly common.
In the previous category, the content is not stored in RSS; the search results are converted to RSS for presentation to the user. RSS-based search engines, on the other hand, index RSS files. The content is usually taken from blogs or other news sites, as these are the most likely to use RSS. Examples are Feedster [25], Daypop [26], Technorati [27] and PubSub [28]. Technorati concentrates solely on blog feeds. Among other useful features, it can track the number of links to any particular blog. PubSub describes itself as the "first large-scale public matching engine". It reads more than two million weblogs and 50, 000 Internet newsgroups, as well as other web-based material. Subscribers indicate the topics they're interested in and are notified as soon as data matching this is read by the engine.
Increasingly, journal publishers and intermediaries are providing RSS feeds containing tables of contents, often with links to abstracts and, sometimes, full text [29]. BioMed Central provides feeds for all its journals [30]. Individual journals, such as Nature [31] and Ariadne [32], also make feeds available.
Peter Suber has created an experimental portal, via RSS, for sample Institute of Physics (IOP) ejournals at the University of Saskatchewan library [33]. Its interface to the New Journal of Physics is shown in Figure 3. Clicking on an article title displays the abstract and bibliographic information and a link to the full text. Content from IOP RSS feeds [34] is used to create the portal but the information is displayed within the HTML using JavaScript.
It's not just libraries that are providing journal or article portals. The Bioinformatics aggregated RSS feeds (BaRf) site [35] provides "RSS feeds of titles and abstracts of the most recent papers published by journals that may be of relevance for people involved in Bioinformatics".
As McKiernan (2004) suggests, RSS could also be used to update an ejournal's holdings within a local OPAC or ILS.
There are dozens of aggregators (RSS readers or news readers) available [36]. They can be categorised as follows:
An easy first foray into RSS feeds is via a web-based aggregator such as Bloglines. Being web-based, there's no software to download and subscribed feeds can be accessed from any Internet-connected machine.
Some aggregators allow the subscriber to decide how often to harvest an RSS feed. In a fit of over-enthusiasm, many subscribers arrange to poll web sites once a minute. However, as Allgood (2004) points out, "responsible citizens" should restrict polling to between every 15 and 30 minutes. Sites will often ban an IP address if it attempts to poll more frequently than every 30 or even 60 minutes. The frequency should be based on how regularly the site updates; what's the point in polling every hour if the data only changes a few times a week?
In addition, the limitations of RSS mean that, if just one item in a feed has changed since the last poll, the entire file must be downloaded. And, if feeds are dynamic, users may find they have downloaded a file in which nothing has changed.
A dynamic feed is one generated on the fly in response to a particular request. For example, MacLeod (2004) reports on new tools for feeds that are customised to reflect the particular interests of subscribers. Such feeds are likely to be dynamic. MacLeod is enthusiastic about the possibilities of this new approach for OPACs, bibliographic and full-text databases, and web directories and gateways. He comments that:
"To some extent, this is already happening, with several RDN Hubs producing RSS feeds of new resources added in selected subject areas or resource types, e.g. EEVL New Learning Materials for Engineering."
<>Note the telltale cgi-bin in the accompanying URL: http://www.eevl.ac.uk/cgi-bin/learn-eng-on-eevl.rssThe concept of dynamic and customised feeds sounds great. But, with current technology, it is likely to involve prohibitive bandwidth consumption. A solution to this problem is needed before such ideas can take off. For now, it is better to generate the feed once as a static file and tune the web server configuration for maximum cachability [42]. It's not as exiting but it's more realistic.
There are five - some say seven - different varieties of RSS 0.9X (Pilgrim, 2004). They are all officially obsolete but 0.91 is still regularly used because of its simplicity. The successor to 0.9X, RSS 2.0, is now owned by the not-for profit Berkman Center for Internet & Society at Harvard Law School (Bowman, 2003). RSS 1.0 was developed separately and is a W3C standard. The rival Atom format, on the other hand, is on its way to becoming an Internet Engineering Task Force standard [43].
All versions of RSS and Atom are written in XML. The main distinction between them is whether or not they are based on the W3C standard RDF (Resource Description Framework) [44]. RSS 1.0 is based on RDF; all the others are not.
RDF is "a language for representing information about resources in the world wide web" [44]. As such, and as a W3C standard, it could appear to be the obvious choice for encoding RSS feeds. Unfortunately, it's not universally appreciated; some feel that RDF makes a complicated job out of a simple requirement. In addition, "the RDF syntax is just too ugly to be plausible" (Harold, 2004).
Atom is the only widely used alternative syndication format to RSS. Among the aims of Atom's developers is the creation of a more tightly specified format, using the best of RSS and avoiding some of the political wrangling surrounding RSS [45]. (Bray (2003) points out that, in some circles, RSS has become a synonym for Reliably Spiteful Squabbling.) Atom was given a major boost when, in January 2004, it was chosen by Google, in preference to RSS, for its recently acquired Blogger Web logging software (Hicks, 2004a). But there are signs that Google is changing its mind and may support both formats equally in the future.
ResourceShelf [46], an electronic newsletter for information professionals, uses Atom-formatted feeds. Atom is similar to RSS but it can support more complex data and so, not surprisingly, is more complex to produce. Some of the earlier aggregators can't read its feeds. However, an increasing number are adding Atom support [47].
Atom's development has, until now, been community-driven (Clark, 2004). In June 2004, the IETF created the atompub (Atom Publishing Format and Protocol) working group [43] as a first step towards creating an IETF standard. The interest in Atom is such that, in May 2004, Eric Miller (2004), W3C's Semantic Web Activity Lead, sent a public e-mail to both the IETF and an Atom mailing list, suggesting that a W3C standards working group be created for Atom instead. In July 2004, Atom supporters turned down the suggestion, choosing to stay with the IETF (Hicks, 2004c).
Now the question is how the Atom syntax will evolve as it moves towards standardisation. Some are pushing for a closer relationship with RDF:
"In my view, syndication is all about saying things about web resources, that is, things with URIs. That's RDF's business and so Atom should be an RDF vocabulary" (Clark, 2004).
Others, such as Dave Winer, co-author of RSS 0.9X and author of RSS 0.2, think not; he has called for an amalgamation of Atom and RSS 2.0 (Hicks, 2004a).
When creating feeds, a good compromise, at present, is to provide two versions: Atom, because it is the newest and most promising format, and RSS 0.91 because it is the most backward compatible. The latter would provide for those older aggregators that don't support Atom; feeds in this format could be discontinued in the medium term if Atom support becomes more universal. However, it is possible that an Atom-RSS hybrid, incorporating RSS 1.0 or 2.0, will evolve, so feed providers must be flexible about future plans.
If a website has associated feeds, there will usually be a link to them somewhere on the home page, often in menu bars or in the footer. The link may be identified by text such as "Syndicate this site". But it is increasingly identified by a small icon, usually orange, sometimes blue, containing the word "XML", "RSS", "Atom" or similar. At present, the most common method of subscribing to a feed is to right click on the link and choose "Copy link location". The location can then be copied into the aggregator's "Subscribe" box.
Some RSS or Atom icons include a picture identifying a particular aggregator; common examples are a coffee cup for Radio Userland and a pill for Amphetadesk. These enable one-click subscription for users who are running the aggregator in question. But, as the number of aggregators increases, so does the number of icons. The Syndication Subscription Service [48] is a response to this proliferation. It is identified by a small green "Sub" icon which, when clicked, displays a page listing some of the most popular aggregators. By choosing the link for the relevant aggregator, the user is automatically subscribed to the RSS feed in question. The "quickSub" [49] JavaScript function is an extension of this idea. It allows the user to access a list of one-click subscription links by simply rolling the mouse over the feed icon. The idea is already being used in the shiftedLibrarian blog [50].
For those sites that don't publicise their RSS feeds so obviously, aggregators such as Bloglines will find related feeds if the user simply enters a web site URL. Web-based services, such as BlogStreet's RSS Discovery tool [51] and Feedster FeedFinder [52], perform a similar task. Alternatively, users can search web-based headline aggregators, such as Syndic8.
If all the above fail, checking whether the web site has an rss directory can sometimes be fruitful. (atom directories appear to be less common.) There's no standard location in a site's URL for the rss directory but it is often directly at the root of the site.
If a useful site doesn't have related feeds, it's possible to scrape the site, that is, create a synthetic feed. As already mentioned, LISFeeds.com scrapes headlines from library-oriented sites. Tools such as MyRSS [53] and the aggregator Syndirella [54] will scrape sites. But MyRSS shows self-advertising. And feeds created by Syndirella will only be accessible to users of that aggregator. Furthermore, scraped RSS feeds may stop working if the web site layout is changed. If the site is that useful, it is usually better to persuade the web master to create a feed [55].
There is no one standard extension for a feed file but, in the case of RSS, it is preferable to use .rss and serve with a MIME type of application/rss+xml. In July 2004, the developers of the Apache and Microsoft IIS Web servers agreed (Bray, 2004) that future server releases would automatically use the correct content type, application/atom+xml, for Atom feeds that use the extension .atom.
<>When incorporating feed links in a Web page, it is becoming increasingly useful to include a link element [56] in the head of the document for each feed, as follows:The RSS/Atom scene is changing fast. Within a year or less, many of the more manual methods of feed discovery and subscription described above may be redundant. New developments are emphasising auto-discovery and auto-subscription. But, for now, all of the methods detailed can be useful.
The XML application OPML, or Outline Processor Markup Language [57], is used to "exchange subscription lists between programs that read RSS files, such as feed readers and aggregators". There is mounting interest in OPML and it could be very useful for library applications.
Nature provides an OPML file listing all of its journal feeds [58]. BaRf also has an OPML file; it contains a list of all journals it supports. An increasing number of RSS aggregators can produce (export) and read (import) OPML files. In Figure 1, the BaRf OPML file has been imported by SharpReader and its contents are listed in the left hand panel.
It is becoming common for users to make their OPML files available online, thus allowing others to subscribe to all the feeds simply by importing the OPML. The Share Your OPML! web site [59] is described as "a commons for sharing outlines, feeds, taxonomy". Anyone can upload their OPML file or submit its URL. At present, only the hundred most common feeds are available for the public to download as an OPML file. But the functionality could be usefully extended to make all submitted OPML files available.
A portal could include a list of OPML files, each of which comprised feeds on a particular topic. For example, SOSIG, the Social Science Information Gateway [60], could make separate OPML files available for topics such as anthropology, economics, education and so on. Each file could contain a list of relevant RSS feeds.
OPML is widely used by subscribers to synchronise feed lists between their computers, for example, between computers at work and at home. Equally, it could synchronise feed lists between all public access PCs within a library. There are numerous potential uses for this simple application.
A recently added feature to the Share Your OPML site is People Like Me [61]; this lists people whose OPML files are most similar to the subscriber's. The idea is similar to the "Customers who bought this item also bought: ..." concept in Amazon.com. Its aim is to introduce the subscriber to potentially relevant new feeds. Again, this could be the basis of many useful library tools.
"When Microsoft abandoned Internet Explorer development to concentrate on fixing the browser's security vulnerabilities, it opened the door to the emerging RSS revolution."
Thus wrote Steve Gillmor (2004) in July. He describes RSS as Internet Explorer's most devious opponent. At present, Internet Explorer has no support for reading or aggregating RSS feeds. Microsoft has indicated that the long-delayed Longhorn, the next version of the Windows operating system, will include RSS aggregation. But, in the meantime, its major rivals in browser technology, Mozilla, Opera and Apple's Safari, are all implementing RSS features.
The new version of the Apple browser for the Mac is Safari 2.0 [62]. It will be released in 2005 along with Tiger, the next version of Mac OS X, and will provide aggregator functionality. One of its most attractive features is the automatic detection of feeds. This is where the use of the link element, as detailed earlier, is important. Safari will only be able to detect feeds automatically if they have a link tag in the head of the referring document.
In addition to this functionality, the server version of Tiger will include a Weblog server.
Opera version 7.50 [63], released in May 2004, includes an auto-detect feature for RSS feeds, as well as auto-subscription. The browser handles feeds within the mail application as if they were e-mail messages. So far, Opera doesn't support Atom feeds but it would be surprising if this wasn't rectified at some point.
Mozilla Firefox 1.0 for Windows and Linux is scheduled for release in mid-September 2004 [64]. It will incorporate RSS functionality (Chu, 2004).
As of August 2004, Firefox is at version 0.9.2 and a free extension called Sage [65] is available which can be very simply installed and provides RSS and Atom feed aggregator functions. The feeds are saved and organised within the browser's bookmarks. This is made simpler by the fact that Mozilla already uses RDF for internal description of bookmarks.
Figure 4 is a screenshot of Firefox showing Sage in action. Near the top left is the Sage leaf icon. Beneath this is a list of feeds. The highlighted feed is displayed in the right hand panel.
Below the Sage icon is a magnifying glass. Clicking on this icon will find the feeds for a particular site. For example, if clicked while the browser was displaying the XML.com home page, the dialog box displayed in Figure 5 would pop up. The latter box lists all the feeds available from the XML.com home page. The user simply highlights the required feed and clicks on the "Add Feed" button. This is one more mouse click than necessary in Safari, which automatically searches Web pages for feeds.
The RSS functionality in Firefox 1.0 will be similar to that offered by Sage, in that feeds are saved within the browser bookmarks. But it will also incorporate Live Bookmark, or Livemark, functionality (Chu, 2004). As with Safari, feeds will be automatically detected only if there is a related link tag in the head of the referring document. If one or more feeds are detected, a yellow lightning icon will appear in the status bar at the bottom left, as shown in Figure 6. Clicking on the icon will list the feeds available. The required feed can then be chosen and stored, as with Sage, in the bookmarks folder. Unlike Sage, each feed appears as a folder and each feed item as a bookmark within that folder. For example, in Figure 6, each of the folders listed under the Livemark folder represents a feed. Item IETF News in Tim Bray's feed ongoing. What.Technology.Atom has been highlighted; if this item is chosen, the related web page will appear in the browser window. As new items are added to the feed by the content provider, the bookmark is updated; hence the name Livemarks.
Whether browser support signals the demise of stand-alone aggregators largely depends on the extent and timeliness of RSS support in Internet Explorer. As Hicks (2004b) points out, Safari, Opera and Mozilla make up less than 6 percent of the market. "Ultimately, what matters is what Microsoft does with Internet Explorer", says Winer (Hicks, 2004b). Future support in Outlook will also be influential.
RSS and Atom are unlikely to become the future of the Web; that would be over-stating the case. After all, there's no transactional component in either; you can't use them to buy a book or reserve a hotel room. But for those, such as librarians, who use the Web primarily to retrieve, provide and update information, RSS and Atom are fast becoming essential communication tools.
Figure 1 The New York Times circuits feed viewed using SharpReader
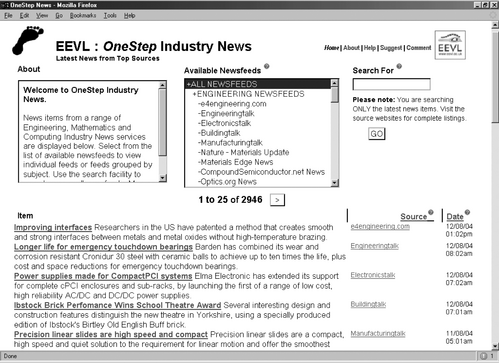
Figure 2 EEVL's onestep industry news service
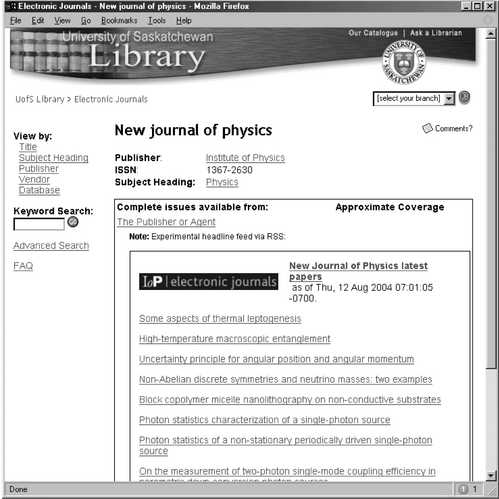
Figure 3 University of Saskatchewan experimental RSS feed
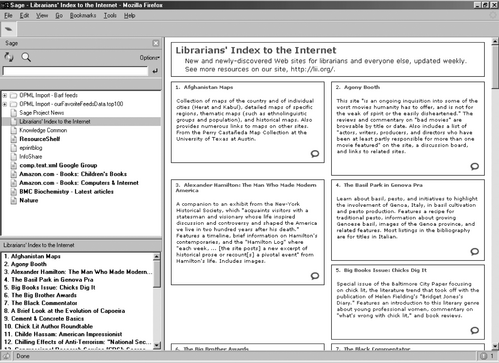
Figure 4 The Sage extension in Firefox 0.9.2
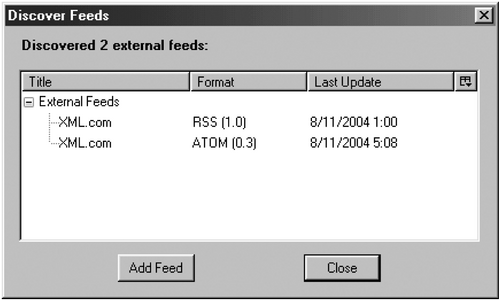
Figure 5 The Sage feed discovery dialog box
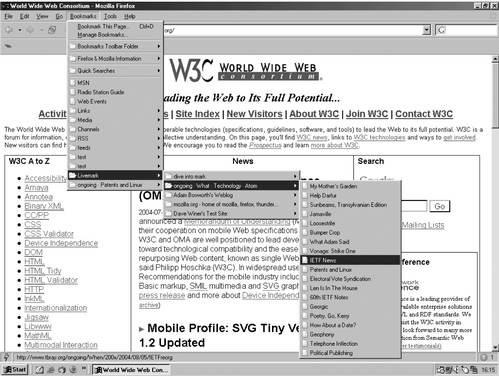
Figure 6 Livemark in Firefox 1.0
NYTimes.com RSS feeds:
http://www.nytimes.com/services/xml/rss/index.html
SharpReader:
http://www.sharpreader.net/
Atom: http://www.atomenabled.org
Rich Sites Services: http://www.public.iastate.edu/~CYBERSTACKS/RSS2.htm
Library Weblogs: http://www.libdex.com/weblogs.html
University of Oxford libraries
Announcements for library users:
http://www.lib.ox.ac.uk/users/news/index.rss
RSS Workshop: http://www.rssgov.com/rssworkshop.html
RSS channel editor and directory: http://rssxpress.ukoln.ac.uk/
Librarians' Index to the
Internet: http://lii.org/
Government of Canada Newsroom:
http://news.gc.ca/cfmx/CCP/view/Welcome.htm
Web Feeds for Books and Monographs: http://www.public.iastate.edu/~CYBERSTACKS/B-Feeds1.htm
University of Kent New
Acquisitions Bookfeed:
http://library.kent.ac.uk/library/newbooks/rss.shtml
Amazon.com Syndicated Content: http://www.amazon.com/exec/obidos/subst/xs/syndicate.html/
Syndic8.com: http://www.syndic8.com/
LIS Feeds.com:http://www.lisfeeds.com/
EEVL's OneStep Industry News service: http://www.eevl.ac.uk/onestepnews/
UKOLN: RSS Channel Presentation
and Searching: http://rssxpress.ukoln.ac.uk/lite/include/
DOIS: Documents in Information
Science: http://wotan.liu.edu/dois/rss.html
Google groups:
http://groups.google.com/googlegroups/help.html
my.PubMed:http://www.mypubmed.com/
Open Archives Initiative: http://www.openarchives.org/
Feedster: http://feedster.com/
Technorati: http://www.technorati.com/
Pubsub: http://www.pubsub.com/
BioMed Central RSS Feed:
http://pscontent.com/biomedcentral.html
Nature: http://www.nature.com/nature/
Ariadne: http://www.ariadne.ac.uk/
IOP RSS feeds:
http://www.iop.org/EJ/help/-topic=rss/
BARF:
http://barf.jcowboy.org/index.cgi/
Weblogs Compendium: RSS
Readers: http://www.lights.com/weblogs/rss.html
Amphetadesk:
http://www.disobey.com/amphetadesk/
Bloglines: http://www.bloglines.com/
UserLand Software:
http://www.userland.com/
NewsGator:
http://www.newsgator.com/
MyYahoo: RSS Headlines Module -
Frequently Asked Questions: http://my.yahoo.com/s/rss-faq.html
Caching Tutorial for Web
Authors and Webmasters: http://www.mnot.net/cache_docs/
RDF Primer: W3C Recommendation
10 February 2004: http://www.w3.org/TR/rdf-primer/
Dave Winer's RSS 2.0 Political
FAQ: http://backend.userland.com/davesRss2PoliticalFaq
ResourceShelf:
http://www.resourceshelf.com/resourceshelf.xml
AtomEnabled Directory: http://www.atomenabled.org/everyone/atomenabled/
Syndication Subscription
Service: http://xml.mfd-consult.dk/syn-sub/
quickSub:
http://www.methodize.org/quicksub/
The shifted librarian:
http://www.theshiftedlibrarian.com/
BlogStreet RSS Discovery tool:
http://www.blogstreet.com/rssdiscovery.html
Feedster FeedFinder:
http://feedster.com/feedfinder.php
Syndirella:
http://yole.ru/projects/syndirella/
Fagan Finder >All About
RSS: http://www.faganfinder.com/search/rss.shtml
W3C: Use < link>s
in your document: http://www.w3.org/QA/Tips/use-links
OPML: http://opml.scripting.com/
Nature Publishing Group
Newsfeeds: http://npg.nature.com/pdf/newsfeeds.opml
Share Your OPML!: http://feeds.scripting.com
Social Science Information
Gateway: http://www.sosig.ac.uk/
Share Your OPML!: People Like
Me: http://feeds.scripting.com/peopleLike
Mac OS X Tiger: Safari RSS: http://www.apple.com/macosx/tiger/safari.html
Opera 7.50 Released:
http://www.opera.com/pressreleases/en/2004/05/12/
Mozilla Firefox 1.0 Release
Plan: http://forums.mozillazine.org/viewtopic.php?t=94779
Allgood, A., 2004, "RSS feed problem; thin clients `jump' instead of (Re)", Web4lib electronic discussion list, 12 July, available at: http://sunsite.berkeley.edu/Web4Lib/archive/0407/0065.html
Bowman, L.M., 2003, "Nonprofit takes hold of blog tool", News.Com (online), 18 July, available at: http://news.com.com/2100-1032_3-1027409.html
Bray, T., 2003, "I like pie", Tim Bray's blog, 23 June, available at: http://www.tbray.org/ongoing/When/200x/2003/06/23/SamsPie
Bray, T., 2004, "Tribal drumbeat", Tim Bray's blog, 21 July, available at: http://www.tbray.org/ongoing/When/200x/2004/07/21/AtomMime
Chu, C.Y., 2004, "RSS feed integration in Firefox", Redemption in a blog site, 13 July, available at: http://blog.codefront.net/archives/2004/07/13/rss_feed_integration_in_firefox.php
Clark, K.G., 2004, "The courtship of Atom", XML.com, 19 May, available at: http://www.xml.com/pub/a/2004/05/19/deviant.html
Fichter, D., 2003, "Why and how to use blogs to promote your library's services", Marketing Library Services, 17, 6, available at: http://www.infotoday.com/mls/nov03/fichter.shtml
Gillmor, S., 2004, "IEs failings point way to RSS", eWeek (online), 8 July, available at:Harold, E.R., 2004, "Re:[xml-dev] Semantic Web permathread, iteration n+1", e-mail to XML Developers List, 3 June. available at: http://lists.xml.org/archives/xml-dev/200406/msg00031.html
Hicks, M., 2004a, "RSS backer seeks merged syndication format", eWeek (online), 9 March, available at: http://www.eweek.com/article2/0,1759,1546077,00.asp
Hicks, M., 2004b, "Apple's RSS embrace could bolster adoption", eWeek (online), 28 June, available at: http://www.eweek.com/article2/0,1759,1618128,00.asp
Hicks, M., 2004c, "Alternate news feed supporters stick with IETF", eWeek (online), 16 July, available at: http://www.eweek.com/article2/0,1759,1624503,00.asp
MacLeod, R., 2004, "RSS: less hype, more action", FreePint (online), No. 161, June, pp. 7-10, available at: http://www.freepint.com/issues/170604.htm#feature
McKiernan, G., 2004, "Web feeds for e-journal issue notification and local OPAC/ILS holdings?, LIS-Forum mailing list, 13 June, available at: http://ncsi.iisc.ernet.in/pipermail/lis-forum/2004-June/000868.html
Miller, E., 2004, "W3C response to proposed Atom Publishing Format and Protocol (atompub) working group", e-mail to Internet Engineering Steering Group, Internet Engineering Task Force, 13 May, available at: http://www.w3.org/2004/05/10-atom
Pilgrim, M., 2004, "The myth of RSS compatibility", Diveintomark.org, 4 February, available at: http://diveintomark.org/archives/2004/02/04/incompatible-rss